I recently upgraded my home desktop with a fancy new SSD. With that came all the advantages of being able to clean house, and start with the latest LTS Ubuntu (20.04).
After upgrading, I decided to (read: was suggested repeatedly to…) start the next steps of getting the tilt sensor to work. Before getting into those details, I had to re-trace my steps. Fortunately I pretty much had everything I needed.
However… when I tried to build the kernel before building a new module, I got several errors:
Well that isn’t good. What gives?
Turns out Ubuntu 20.04 uses a newer version of GCC. Specifically right now, it runs 9.3.0.
My old HD ran Ubuntu 18.04, and that ran GCC 7.5.0. Seemingly there was an update in there that broke compatibility with old kernels.
I’d somewhat expected this – Seemingly I got lucky the first go around. The next options are to:
Install a VM for compiling. Not something I want to do since I’m getting more and more against VMs in lieu of Docker.
Compile natively on the Beaglebone. This one seems like a step backward at this point.
Install an older version of GCC. Probably doable, but more trouble than it’s worth.
Create a Docker image to do build. This one feels like the right thing to do.
Well, I’d opted for #4, but didn’t get too far. Someone else has already done the work for me. He is giving credit to the Raspberry Pi community for getting most of it off the ground, but I’m sending my gratitude.
So the instructions there are pretty clear. Just run the bbbxc script before the make call. I can also just run the command arm-linux-gnueabihf-gcc –version and see that the image is running GCC 4.9.2. That also matches which compiler was used for the beaglebone kernel itself. Cool!
And that’s it for this one. Just run the command “./bbbxc make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf-” and the kernel builds without warnings.
A couple things to note: The container uses the hard-float compiler. From my brief research, it seems like the BBB has the hard floating point architecture. So hopefully I’m good there.
The other thing that I need to figure out: The KDIR argument to a module build. Currently the bbbxc script seems to mount everything from my current working directory down, but that might not be the case. I tried soft linking in the kernel directory, but that didn’t work. Only a full copy of the kernel directory made things work.
I suspect that’ll be an easy fix once I find it. I haven’t spent any time yet in this quest though.
The next step will be to implement a driver for the tilt (power) sensor. Hopefully that’ll come up really soon!
There’s a number of decisions that can be made at this point. The Beaglebone has HDMI out. There are all sorts of LCD screens made for the device – some of which have touchscreen… There’s also a webserver option, but I feel that’d force me down the road of web design or iOS app development.
I did want to stay in the Embedded Linux world though. Just plugging in an HDMI as the output seems like a waste. I also wanted to at least start with stuff I had lying around. Fortunately, I had one of these displays lying around.
A display similar to what I had lying around
Perfect. Hardware found. If I want to display RPMs, or power, or cycle through a few different things, this 32-character display should suffice. I wonder if there’s a Linux driver for a 16×2 LCD driver out there…
Well that first result looks nice. I should be able to start with this. I wonder what it was created for…
Readme snippet of the driver
Oh wow. I’m running the 3.8.13 kernel on the Beaglebone Black. So it seems like this driver is pretty much the perfect fit!
The same steps from the GPIO were necessary.
Setting up a device tree overlay to configure the pin mux.
Configuring any parts of the driver that might be necessary.
Compiling and inserting the kernel module.
Testing and implementation
Setting up the Device Tree Overlay
The driver has hard-coded pins compiled in.
There’s no feedback from the LCD, so it is probably safe to assume they’re all outputs from the processor. Plus if you look at the fact that each pin calls gpio_direction_output, you can put two and two together. Each of these six pins then need to be configured as outputs. But there’s a bit of info needed for the device tree to be configured.
This site contains the GPIO mapping to their relative offsets in the CPU’s GPIO module. Yes, the processor’s TRM also has this information, but I read those enough in non-leisure environments. I don’t care to poke around those in my free time if I can avoid it.
The first pin – the reset pin – is GPIO 67, and is labeled as P8_8. Basically this is pin 8 on the connector 8. I can verify with that table here that Pin 8 (the last row photographed here:
Pin 8, showing offset 0x894
… does in fact match GPIO 67
Pin 8 showing GPIO 67
So I decided to trust this info, and what I was specifically looking for is the offset of 0x894 I mentioned in the caption above.
Comparing that table against the device tree overlay from Derek Molloy’s blog, I figured that I needed to subtract 0x800 from that offset. I can’t say I’m positive as to why that’s the case, but it is. With all that in mind, and going over all the pins, I came to this overlay:
Alright. Hopefully this worked…
Configuring the driver
Well this is a short section. It turns out I didn’t really have to change anything. None of the pins used for this driver overlapped with ones I’m using. I could change the pin numbers to module parameters. Meh… no need at this point. On to the next part.
Compiling the driver
On to the next step. For GPIO tachometer driver I’d started with the source and a makefile that built on the target itself. So I’ll just copy this over to the target, run make, and end up with a .ko file.
KLCD module makefile
So another decision to make. Copy the file to the target and write a new makefile to build locally, or step up to the plate and finally set up a cross-compile environment. I decided to do the latter.
I had to figure out what version of the kernel I was running. A simple “uname -r” told me I was running 3.8.3-bone86. I need to pull down these sources locally, and they can be found at https://github.com/beagleboard/linux. A simple checkout of the 3.8.13-bone86 tag should be what I need.
Next, I need to configure the kernel in the same way that the Beagleboard was configured. This can be pulled from the Beaglebone itself, and can be found at /boot/config-3.8.13-bone86. I can copy this file to the .config and boom, the kernel is configured to compile for this device.
Throughout all this, I’d had to install cross compile tools. Specifically the arm-linux-gnueabi- toolchain. Then the single command “make -j6 ARCH=arm CROSS_COMPILE=arm-linux-gnueabi-” will spin up a number of threads to compile the whole kernel.
Lastly, to compile the kernel module I found myself needing to modify the path in the Makefile:
Modified makefile
With that Makefile, and the kernel checked out and compiled in the KDIR directory:
KDIR contents
I was able to simply run make in the kernel module directory to build the .ko from my main machine:
The klcd.ko build
Copy the .ko file over, and run an insmod and the KLCD device shows up in /dev.
Better yet, running echo “Colin Here” into the device actually works!
The command to write to the display / device driverThe device showing the message!
Tying it all together
So now there’s a driver for measuring the GPIO, and a driver to display the events. At this point the program is incredibly straightforward. Read the speed and display it.
Sticking with the cross-compile technique, I made a simple Makefile:
Simple cross-compile makefile
There’s a little bit to the program insofar as signal trapping, but the main loop only consists of the read and write:
The main loop
Ok, so it isn’t a “write” per se, rather an ioctl. I think a write / seek would work, but the reference app that came with the driver uses ioctl all over the place. I followed suit here.
The last steps can be found all over the internet, so I’m not going to detail them. Adding the overlays to be persistent, inserting the kernel modules at boot, and starting the monitoring app. That’s all that is needed for phase 1!
As I mentioned in Exercise Bike Upgrades, step 2 is getting the data into a computer. I’m starting at a point where I’ve got a signal coming off the bike – a discrete 0 or 1 based on zero or infinite resistance on a wire. I need to process this signal and get it into a format that it can be displayed to a user. How this’ll be done depends slightly on what I’ll be using as my computer. I’d like to learn and try new things on this project, but I don’t want to bite off more than I can chew. There’s an end-user who is expecting a product, after all!
Choosing a computer
The whole purpose of this is to keep the budget reasonably low. This means limiting my “computer” selection to what I already own. Fortunately there’s a fair amount to choose from.
Option 1: Raspberry Pi.
I have a bunch of these lying around. They’re cheap, powerful, and typically run full displays to an HDMI output. Things I’ve done with RPis in the past have involved KODI clients, small webservers, and kiosk-like interaction. The RPi is a fine choice but I’m a little averse since I’d probably find myself just writing python scripts. Been there, done that. Also I’ve used the RPi a lot, I’d like to try something new. Plus there are a lot of super easy projects to drop into a Pi – why tie one up with this project when I don’t have to? So I opted out of this one.
Option 2: FPGA Dev Boards.
I’ve acquired a number of FPGA dev boards that run Linux in the past few years. A Snickerdoodle and some Zedboards of different types are cluttering my desk. I have found absolutely no use for them yet, and this might have been the perfect opportunity to do so.
I have a growing amount of indirect experience with FPGAs – enough to have pulled the basics. Depending on the frequency of the level changes, an FPGA might be necessary.
For example: A quickly changing setup might require dedicated hardware. A product I’d worked on a lifetime ago utilized the Sensoray 2620 encoder counter. There might have been jokes made about how “Sensoray” sounds like a weapon from a D-grade SciFi movie. Looking back, that project was pretty bad-ass, but I digress… That hardware can handle frequencies of 2.5 to 10 MHz! Nobody is pedaling that fast.
An FPGA can approach those speeds without additional hardware. It could react to the input and logic to return state change counts could be implemented. This would be a learning experience, and is not very portable. Essentially – it is probably overkill. I’ll keep it in my back pocket if it becomes practical.
Option 3: Arduino
I have a few Arduinos lying around. The programming doesn’t really interest me though. They’d work, but would have bottlenecks when getting data from the Arduino to somewhere else. For example, if a webserver is ever expected to be used, Arduino would not suffice.
Option 4: Particle
I didn’t consider this since I don’t have extras lying around, but a Photon would probably be a great option. It has the same “webserver upgrade” limitation the Arduino option would have, but would be able to work indirectly through particle’s services.
This would be a good option for a quick solution, but wouldn’t be transferrable to other environments.
Option 5: BeagleBone
The last main option, and the one I went with, is the BeagleBone. I have a couple lying around, haven’t used them much, and they run Linux.
It isn’t very different from the Raspberry Pi. It runs Linux. It is supported by the community. The Beaglebone does have twice as many IO pins as the RPi, though I don’t think I’m that resource-constrained at this point.
Primarily my choice of BeagleBone over RPi was to avoid the temptation to go to GUI + Python. I knew I wanted to write kernel drivers, and more often than not the Pi users write several abstraction layers above this.
So I decided to try to start the project with the Beaglebone. Hardware Selection done!
Recording the data
With computer selection done, the next step is to get this into the system. With regards to the sensor, there’s a signal that is usually 0, becomes 1 for a brief moment, then goes back to 0. If we can count the number of times the signal goes from 0 to 1, that is a direct indication of how quickly the flywheel is spinning. One way this can be done is through sampling.
In a sampling configuration, we’d write a program that checks the level of the pin at specific intervals. When the level of the pin changes, we’d make note of this. The number of transitions over the last period of time would indicate how quickly the wheel was spinning.
For example, if you’re sampling at 100 samples / second, and there were three instances where the signal went from 0 to 1, you’d know that the flywheel was spinning at 3 revolutions per second.
There’s a huge downside to this though. In the case above, we’re taking 100 samples per second. Of those 100 samples, only the three transitions from 0 to 1 matter. So we’re maybe running at 5% efficiency. Further, there is the possibility of missing a measurement, particularly if the duty cycle is not at 50%.
In other words, it might be efficient to poll a signal that goes “0000111100001111”. But it would not be efficient to poll a signal that goes “000000001000000001”. The probability of missing that short-lived “1” is high, and will compromise your data while wasting a lot of CPU time. So in this case: don’t do that.
Since polling doesn’t really make any sense, I looked to trying to implement interrupts in order to trigger an event. Instead of having to come back all the time, the CPU could just count the number of times the interrupt has happened. That would allow me to check, at any time, how quickly the flywheel had been spinning. Much to my delight, this turned out to be fairly easy to implement.
Implementing the input software:
With many thanks to this blog by Derek Molloy, I was off to the races in doing the two things needed to configure the system: Setting up the necessary pins for inputs, and actually writing the driver software.
By default, CPU pins have a defined mode. In this case I needed to choose a pin that would act as my input. Basically, since the example in Derek’s system had used GPIO 15, I followed suit.
There was one difference between Derek’s code (as well as my initial test setup) and my final implementation. The initial system I had put together had a GPI tied directly to a GPO. This way I could toggle the GPO a number of times, and verify that the GPI was seeing the changes. The final implementation had a connected circuit followed by a disconnected circuit. So for this I’d decided on an internal pull-up on the GPI, with a ground signal connected to the other side of the reed switch.
Changing this configuration in the device tree, I simply ran the file through the device tree compiler, and was able to apply the device tree overlay to the system. Derek’s blog has all the info for that.
Writing the driver:
Now I have a signal going into the pin. It seems to be clean – no debouncing needed at my speeds – so I’m on to making the driver. The way that I think the driver could be most useful is this:
A character driver interface. This way my application only needs to read from a file.
Limited ioctl control. I much prefer read / write when it can be done.
Reads would return the number of times the interrupt had happened over the last period of time.
Before a character device can show up, it needs to go through the module_init. This is basically where the driver tells the system “I am a driver of this type” and will verify any resources it needs.
First, setting up the input. When setting up the pin to be a GPIO, the system could either be input or output. And the kernel doesn’t even recognize it as such. So the driver will verify the GPIO selection is valid, claim it, set it as an input, and export it so that it shows up in the /sys/class/gpio directory.
Setting up the GPIO pin for input
The pin can then be tied to an interrupt and function, with gpio_to_irq and request_irq
Setting up the IRQ
Since the GPI is set up, the driver can be registered to a file. I got a little experimental (and subsequently lazy) at this point. I’d tried to make it possible to have multiple GPITACH devices, but I think I got some pointers wrong. Since I don’t have a use-case, I figured I’d leave it for later. Maybe I’ll extend the behavior at some time. Probably not.
Anyway, the code with some error-checking goodness is as such:
Character Device Creation
From this, a file will be created at /dev/gpiotach1.0. Before looking at the interface to this, the interrupt logic needed to be created.
Interrupt routine:
My desire was this: At any time, the application could read from the file and know how quickly it is going. I didn’t want to rely on the application managing any time. An example of this would be the IRQ would just increment a counter. Read the counter at different intervals and you can deduce the speed.
What I’d rather have is the driver keeps track of when each interrupt happens. In this case, the old entries would “expire” and new entries would be added in. The way I achieved this was to use an array (or rather, circular buffer) of ktime measurements.
KTime malloc
Using the circular buffer from the Linux kernel, items can be added to the head with this routine:
Adding an item into the circular buffer
For the add routine, I’d decided to add my expiration time to the measurement. Essentially I took “currentTime + 3 seconds” and added that to the head of the circular buffer.
Calculating current and future times
Armed with this, I can purge expired times from the buffer:
Purging old time entries
So by purging old times and pushing new ones as they happen, I can just look at the circular buffer count. This count will be how many times the interrupt has happened in the last 3 seconds. Perfect!
Finalizing the character driver:
Lastly, the open, read, write, and close routines must be written to finish off the driver.
Character driver functions
Open and close don’t really do much. In the case where we’d have multiple potential instances, this might manage some memory, mutexes, etc. This doesn’t really do that – at least not well.
Similarly, writing doesn’t make much sense to this. I suppose the write could act as some sort of configuration instead of ioctl. Right now it only clears a counter that is otherwise unused.
Reading is where the magic happens. Magic because of the simplicity. Essentially it just purges out any remaining expired times and returns the buffer count to the user. Throw in some mutex protection for the IRQ-accessed buffer and that’s it!
Final reporting of the count to the user
The full driver can be found here. I referenced the code from September 1, 2020. It might be expanded or cleaned up at some point.
Compiling the driver
This one was easy. I’d started using Derek’s suggestion from this part of his blog to compile the driver on the target. This might not be the fastest way to compile the driver, but it sure was easier to get set up. The next step in this project might include setting up a cross-compile environment.
We’ve recently acquired a Schwinn spin bike as a way to exercise during quarantine. Although I haven’t used it yet, I’ve taken on the role of adding some sort of feedback – namely speed and resistance. The bike doesn’t have this feedback natively, but can be upgraded for a mere $600. That’s too rich for my blood, so I figured I’d use some parts I had lying around and try to recreate the full spin experience.
Also the thought of having a nerdy embedded Linux project that is wife-approved doesn’t sound too bad.
The problem can be broken down three main parts. Each of these parts have nuances to them, but in general they are:
Getting data out of the bike
Getting data into a computer
Getting data to the user
For step 1, we’ll need to start with the bike itself.
The Bike
The bike itself it a Schwinn Carbon Blue. It contains a main wheel with a star pattern on the front, and a knob that can be turned to adjust the resistance. These are the two things that can be monitored to provide full feedback. Speed (RPMs) can be measured by counting the wheel rotations. Power (as well as “calories”, and “distance”) can be measured by a combination of speed and resistance. We need to figure out a way to get these signals from the bike to a wire. Starting with what I’d consider the easier of the two tasks, I decided to try to grab RPM data.
My first attempt at measuring RPMs failed. I’d made the assumption that the star pattern was the secret sauce that was being used to measure speed.
The idea here being that the silver pattern in the middle of the wheel would be reflective to an LED, and the red pattern would not. This would translate to a 1 state and a 0 state – something that easily translates to a computer. Also, this hardware is fairly common, and cheap so I thought this would be a hole in one. I ordered some parts, hooked them up to a DMM and hoped to see a huge signal change between the red and silver state.
I was wrong. There was no noticeable difference between the two parts. I found that the sensor could distinguish black and white quite reliably, but not silver and red. I poked around a little more, but couldn’t find sensors I’d needed. I decided to take a step back and see if I could find any more information on how the system worked.
This was definitely the most useful thing I’d found. When you look through the install instructions of the “RPM sensor,” step 19 tells you the answer:
“The sensor magnet that is embedded in the flywheel.” Interesting… I’d thought the manufacturing process of putting some sort of magnet would be cost-prohibitive. I must be wrong. Otherwise, manufacturers take note. This might be an opportunity to cut cost.
Ok, so there’s a magnet. Now we need a way to make our 0 or 1 states to be “are we near the magnet, or are we not”. Not being a mechanical sensors expert, I’d expected a hall-effect sensor or something similar. At this point I’m getting more concerned about mounting the sensor to the bike. Maybe there’s a way to solve the sensor issue and the mounting issue in one fell swoop.
The second manual I’d found has an interesting piece of information: Part Numbers. With the part number of the sensor in place, a quick Google actually leads to a website that sells those replacement parts individually. It might be cheating, but I’m 100% on board. We ordered two of these (since I’ll probably eventually break one) and received them a few days later.
As it turns out, the electro-mechanics behind the sensor is actually a Reed Switch. I was expecting to have a three-wire interface to an active component (power, ground, and signal) but I’m glad to know that I only need two. As Forrest Gump would say: “That’s good. One less thing.”
The Reed Switch PCB
So I installed the switch and tied leads to a DMM. Just testing for connectivity with the buzzer here, the system seemed to work very predictably:
From that video the behavior of the system can be deduced. The Reed Switch is connected (the beeping noise) once per revolution, and disconnected the rest of the time. Compared to my initial “reflectivity solution” method, this has lower resolution. It does a full transition cycle once per revolution whereas my initial design had four. There really isn’t much of a benefit in this case. The feedback loop of sensor > computer > screen > human > pedals isn’t sensitive enough to that level of precision.
At this point, step 1 is complete. We’re able to get speed data off the bike. Note that I’m ignoring the power data for now – that’ll be done in a later phase. We should be able to get the connected / disconnected signal into a computer. That data will directly lead to flywheel speed and the speed we’re interested in: the pedal speed.
Getting this into the a computer is where most of the time has been spent thus far, so that’s going to be a separate post.
A friend of mine is creating an Arduino-based monitoring system for their garden. The input will be a humidity sensor and the output will be a simple flow controller to a tank of water (solenoid).
Sure, that is great when you want to just have everything “work” but I’d like to take it a step further. I want to be able to verify that it works (aside from, of course, looking at whether the plants are dead.) So to achieve this, we’ll need plots.
The Desired Goal
Over time, we’ll be collecting data. This could be live (via a wifi connection) or on-demand (via a USB connection or an SD card.) Either way, a simple plotting interface where a metric could be selected, and a date range could be specified would be an ideal interface for this type of system. Essentially a simple look like this:
From this, a metric like “humidity” or “valve state” could be selected, and a date range specified. A super crude MSPaint-like example would be something like:
From that type of plot you could easily infer things like when it rained and whether or not the system is actually functioning.
The Building Blocks
In order to achieve this goal, there are four essential pieces that need to fall in line. These are:
Data recording
Data transfer
Data storage
Data visualization
Data recording is inherent to the Arduino, and is not something that I’m concerned with.
Data transfer is another piece of the architecture I won’t be concentrating on. This is because it should be trivial when 1 and 3 are in place. It’ll either be a periodic MYSQL function call, or a script that parses and inserts data to a databse.
Where my (very limited) experience can be of most benefit is in the data storage realm. This will likely bleed into the (Pun Alert!) uncharted territory of Data Visualization.
An Aside
To me, this seems like it must be a problem that everyone has solved a million times over. There should be a pre-built LAMP instance that does this. Unless I’m looking in the wrong places, I can’t seem to find a simple one. There are things like Weave that seem to be an open-source alternative for Tableau. This seems like overkill.
There is no shortage of potential solutions. Other suggestions include GNU’s gnuplot, or the Python MatPlotLib, or even my favorite: GNU Octave. but all of this seems horribly inefficient. Maybe my ignorance of web development is really showing, but none of these feel like the right solution. Alas, I’m moving forward with my intuition that a MySQL database will be necessary and the last piece of the puzzle will just fall in place.
(Note: After starting this post, I found this solution, which seems to be a pretty awesome starting point)
Data Storage
Starting with what I know, I’ll want to implement a database. My experience has been almost exclusively in MySQL, so I’ll start with that. I should start with a container, but at the risk of losing some 1337 points, I’ll start with a VM. In this case, Xubuntu 18.04 because… why not?
Install MySQL
Here’s the easiest part of it all. Just install MySQL Server on the newly-created VM with the command
sudo apt install mysql-server
Another helpful tool is mysql-workbench. Install that with
sudo apt install mysql-workbench
Those two installs take up a cool 350MB of disk space, so it takes a minute or two minutes to install.
Then you’ll need to create a user:
echo "CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';" | sudo mysql
After that, you can run mysql from your user’s account with:
mysql -u username -p
Create The Database
We’ll need a simple database, with a simple table as a proof of concept. When the project blows up to include multiple solenoids, sensors, arduinos, etc. this won’t suffice. But that’ll be another project of its own.
In order to not break MySQL completely open, we’ll want to use the root account to create a new database. This DB will be fully controllable by the account we just created, but we don’t want EVERY database on the server to have this hole. So for this:
echo "CREATE DATABASE sampleDB;" | sudo mysql
echo "GRANT ALL PRIVILEGES TO sampleDB.* TO 'username'@'localhost';" | sudo mysql
Now you have the ability to move to the next step:
Create The Table
Now we can start using the database. For this instance, it might help to think about the “database” as an Excel Spreadsheet, and the “table” as “Sheet 1” of the XLS. Many Excel spreadsheets don’t go past Sheet 1. At lest most of the ones I use.
Anyway, from here we can enter the MySQL prompt. Every line will have this at the beginning, which I’ll omit in the future.
mysql>
Create the simple table that contains a date, a humidity value, and a control value:
CREATE TABLE sampleTable (pk INT NOT NULL AUTO_INCREMENT, time DATETIME, humidity INT, control INT, PRIMARY KEY (pk));
You should then see that the table was created from the command
SHOW TABLES;
Add some data
To finish this side of things, we need to add a couple of sample values. At least two so that a plot can be made. For this, a simple insert should suffice.
INSERT INTO sampleTable(time, humidity, control) VALUES (CURDATE(), 100, 0);
INSERT INTO sampleTable(time, humidity, control) VALUES ("2018-04-28 01:00:00", 95, 1);
This should leave you with two values inserted in the table. From here, simple 2D plots can be made!
These insert commands are essentially what will be used to log all data moving forward.
Prepare The Front End
At this point, I’m in uncharted territory. Fortunately, the post I found has some pretty straightforward suggestions, which I’ll use as a base. First, install the webserver.
sudo apt install apache2
After this, you should be able to navigate to the loopback address (127.0.0.1) from a web browser. Look for the “It works!” message.
At this point, we have the LAM part of the LAMP server functional. The last piece of that which is necessary is the PHP. This can be installed by running
We’re finally able to plot stuff. The last thing is to request what we want to plot from MySQL. For this, I came up with the smallest example I could make to a file inside var/www/html:
<?php
require_once ('jpgraph/jpgraph.php');
require_once ('jpgraph/jpgraph_line.php');
require_once ('jpgraph/jpgraph_error.php');
$servername = "localhost";
$username = "colin";
$password = "password";
$dbname = "sampleDB";
$y_values = array();
$x_values = array();
$i = 0;
// Create connection
$conn = new mysqli($servername, $username, $password, $dbname);
// Check connection
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
// Run the query
$sql = "SELECT time, humidity FROM sampleTable";
$result = $conn->query($sql);
if ($result->num_rows > 0) {
while($row = $result->fetch_assoc()) {
//echo "when: " . $row["time"]. " humidity " . $row["humidity"] . "
";
$y_values[$i] = $row["humidity"];
$i++;
}
}
// Close the connection
mysqli_close($conn);
// Make the graph
$graph = new Graph(800,500);
$graph->img->SetMargin(40,40,40,40);
$graph->img->SetAntiAliasing();
$graph->SetScale("textlin");
$graph->SetShadow();
$graph->title->set("Example");
$graph->title->SetFont(FF_FONT1,FS_BOLD);
$graph->yscale->SetGrace(0);
// Make the plot
$p1 = new LinePlot($y_values);
$p1->mark->SetType(MARK_FILLEDCIRCLE);
$p1->mark->SetFillColor("red");
$p1->mark->SetWidth(4);
$p1->SetColor("blue");
$p1->SetCenter();
$graph->Add($p1);
// Draw everything!
$graph->Stroke();
?>
This creates the simple plot of the two values we’ve entered.
What’s Next
To learn PHP, I guess…
It seemed like I couldn’t print info and plot from the same interface. Perhaps that means that everything shown on the screen has to be it’s own PHP file. In that case, this graph could be embedded into any other site in a hierarchical manner.
Otherwise, the next steps would be to:
Add the ability to export the data to CSV
Correct the X-axis. It currently plots against the index
Add a start date and stop date
This would be a parameter passed into the PHP script?
After a little time and a couple of attempted optimizations, I feel it is time to take a step back. This post will be more analytical, specifically addressing the question “Is this even possible to solve?”
How big is this problem?
At the time of the data collection, there were 291 unique Phish songs and 1,622 Phish shows. Throughout the 1,622 shows, a total of 25,169 songs were played, for an average of 15 songs per show.
So, now we have 15 songs played per show. Let’s use this to say that if we’re “visiting” a show, it will take at least 15 operations to “mark” each song as “visited”
Terminology
I apologize, but feel I must adjust my terminology. Phish fans will say “I’ve been to X shows and never saw a Fluffhead.” I plan to use this type of mentality rather than the iPod mentality I started with. So from now on, the main question will be “What is the list of Phish shows I should have attended in order to see at least one of every song?” I feel it lends itself better to “attend” shows and “see” songs. It has more of a je ne sais quoi than “installing” shows and “having” songs.” The term I used earlier of “visiting” comes more from algorithm studies, and feels too generic.
So now we’re as cheap as we can be. We want to buy as few tickets as possible in order to see every song Phish ever played live. I’m sure you can relate!
Back to it
So it takes 15 “operations” per show. This is essentially taking your book of songs and marking “yep, I’ve seen that song” once for every song. This is “seeing” a show.
Since I’m currently doing a recursive algorithm, if I see that attending the show won’t help me solve the problem, I’ll have to un-attend the show. This’ll be another 15 operations to say “nevermind, I haven’t seen that song.”
So we can essentially say that we’re at 30 operations, for every show we want to try to attend. Great!
How many shows do we need to attend
So the greedy algorithm solved the problem in 71 shows. I know it can be solved with a little modification in 70 shows. I know the problem cannot be solved in 60 shows. My guess, based on no other information whatsoever, is that it’ll probably take about 67 shows.
An assumption that can be made is that we’ll only need to consider the 67 fewest played songs. Call this “Assumption X.” This is a very strong assumption, and every time this assumption is violated in practice the number of required operations will multiply. We’ll still make Assumption X for a baseline.
So, looking at the first 67 songs, we can see how many times each of them were played. By my count, there were 36 songs that were only played once. There were 17 songs that were played twice. Ten songs were played three times, and 11 songs played 4 times.
So to get to our estimated 67 shows, we need 36×1, 17×2, 10×3, and 4×4 songs vs the number of times played.
We don’t really care about the 36 songs that were only played once. We know for a fact that each of those shows are in the list of tickets we need to buy. So let’s look at the songs that were played twice.
Seventeen songs were played only twice. Let’s start by looking at two songs: Song A and Song B. Song A was played at Show 1 and Show 2. Song B was played at Show 3 and Show 4.
If we want to see both Song A and Song B, we’ll have to attend either:
Show 1 and Show 3
Show 1 and Show 4
Show 2 and Show 3
Show 2 and Show 4
To extend this to a third song Song C (played at Show 5 and Show 6), we’ll need to double the number of combinations to check.
Show 1, Show 3 and Show 5
Show 1, Show 4 and Show 5
Show 2, Show 3 and Show 5
Show 2, Show 4 and Show 5
Show 1, Show 3 and Show 6
Show 1, Show 4 and Show 6
Show 2, Show 3 and Show 6
Show 2, Show 4 and Show 6
The astute reader would notice the list size doubles every time another twice-played song needs to be checked, and that is precisely the case (in the best-case scenario.) So after the 17 different songs played twice, we have 2^17, or 131072 different combinations. This is a cakewalk for any computer to test.
However, we’re only at 53 shows. We guessed we have to get to at least 67. Each of the thrice-played songs triples the number of combinations played. So to get to 63 songs, we’ll have to test 2^17 * 3^10 combinations, or 7,739,670,528 different show combinations!
Seven billion still isn’t a huge number for a computer. Assuming an algorithm that can run around 1GHz (one billion operations per second) we’re only at 7 seconds worth of operation time attending shows. Of course, we still have to perform 30 operations to mark each song as seen.
The last four songs were played at least 4 times. So we’re at an absolute best combination number of 2^17 * 3^10 * 4^4, or 1,981,355,655,168, or about 2 trillion combinations.
Best case scenario, at 30 operations per show attended, 2 trillion combinations, and 1 billion operations per second, we’re at about 60,000 seconds of computation time. 17 hours.
Wait A Second…
“In your example, you said Song A was played at Shows 1 and 2, and Song B was played at Shows 3 and 4. What happens if there is some overlap?”
This type of scenario doesn’t affect the assumption that we need to see 67 shows to see every song. So in the case that Song A and Song B were played at the same show, we’ll now need a four-time-played song to take the place. So our 17 hours just became 34 hours. (2^16 * 3^10 * 4^5; * 30) Nice try though. I’ll get to how quickly this blows up in practice shortly.
Pruning the tree
After all of that data collection, there are still a lot of songs that were only played once. For instance, the song Fluff’s Travels was only played one time. (Whether or not it is due to shoddy record keeping of a partial show recording in the late ’80s is not something I’m going to discuss.) So since we know that we’ll have to include that show, why should we even care about, say, Bathtub Gin?
This is exactly what I’ve done here: (or at least tried to do…)
private static int selectAllSinglePlayedSongs() {
int numShowsSelected = 0;
for (Song song : songList) {
if (song.listSize() == 1) {
Show currentShow = song.getShowList().get(0);
if (!currentShow.isSelected()) {
numSongsLeftToSelect -= currentShow.select();
numShowsSelected++;
}
}
}
return numShowsSelected;
}
private static void pruneShowSetlists() {
for (Show show : showList) {
show.pruneSongList();
}
}
private static void prunePlayedSongs() {
Iterator<Song> songIter = songList.iterator();
while(songIter.hasNext()) {
Song currentSong = songIter.next();
if (currentSong.isSelected()) {
songIter.remove();
}
}
}
// Select all of the single-played shows
// Select all songs covered by those shows
int numShowsSelected = selectAllSinglePlayedSongs();
// Remove all those songs from the show setlists
pruneShowSetlists();
prunePlayedSongs();
After running this routine, I’ve gone from a list of 291 songs played a total of 25,169 times down to a list of 102 songs played 2,177 times. This removed 27 shows. So now to hit the “magic” number of 67, I only have to find 40 new shows. This should be easy now…?
Analysis of the new tree
Things haven’t actually changed too much. In fact, I think they’re “worse.” Here’s why:
On the initial analysis, I’d assumed that all 37 songs that were played only one time would count toward the 67 shows needed. In fact, only 27 shows were needed. So we’ll need 40 shows from the new distribution. Before pruning this was:
34 songs have been played 1 times
16 songs have been played 2 times
11 songs have been played 3 times
10 songs have been played 4 times
11 songs have been played 5 times
After pruning it looks like this:
15 songs have been played 2 times
8 songs have been played 3 times
7 songs have been played 4 times
11 songs have been played 5 times
And while our first solution was 2^17 * 3^11 * 4^5 (plus the 34 single-played shows for a total of 67) it is now 2^15 * 3^8 * 4^7 * 5^10 different possibilities… in the best-case scenario. This is about 3.5 * 10^19 different combinations! Written out as 35,000,000,000,000,000,000. With one computer doing one billion tests per second, it would take 3.5*10^10 seconds. That is about ten million hours of computing time. One thousand years.
One last thing to note: The measured speed of the program is 3*10^7 tests per second, not 1 * 10^9. So there are a couple more orders of magnitude needed to get squared away.
Current Metrics
Currently I’m testing about 15 million combinations per second. Testing combinations of 60 shows took two minutes. 61 shows took 13 minutes. 62 shows took 106 minutes, and 64 shows took about 1000 minutes.
This rate of growth is to be expected. Each extra show is taking about a factor of ten longer than the previous step. At this rate it seems like testing 65 shows will take a week. 66 shows would take two months, and 67 shows would take two years.
Two years? Why isn’t it one thousand years?
I’m still running my early exit routine, which tries to stop going down paths that seem to be failing. Also, some combinations are probably not possible, though I’ll have to look into that more. Lastly, I was assuming that the factor of ten would continue to be the grow rate. This would likely not be the case, as the early exit routine would start allowing more paths. Also, we’d see more of the cases where the “ideal” songs would have already been selected, which we saw was a bad thing. So maybe two years is a little nice of an estimation.
Next Steps
The next thing that I’d like to do is get some visualization tools in the problem. Something similar to Graph Stream seems to make sense, and is probably easier to visualize than something like graphviz .
The other thing I’d like to do is get the recursive algorithm running in parallel. This involves the fairly easy problem of being able to create copies of the tree. The tricky part would be to create an inter-process communication to say “You try that path, I’ll try this path.” I feel like there will probably be enough in that to merit its own post.
A little while back I was involved in a casual conversation. As they often do, this one led to a reference of a specific Phish song. Our next logical step was to attempt to listen to said song. Unfortunately, despite a fairly large category of Phish shows, this specific song was not in the library. We had no internet connectivity, so we were left only what was in the catalog for the rest of the night.
This led to an inevitable question: What is the list of shows necessary for you to have at least one copy of every song?
Many people would simply walk away from that night never knowing the answer. I couldn’t help but give it a shot.
The Problem
To reiterate the problem: Find the shortest list of Phish shows that would contain at least one of every song.
Fortunately this is a problem that can be broken down to several, more manageable tasks. Or at least I had thought so, but I’ll get to that later. The most obvious steps were to:
Get a list of every Phish song
For each song, find the list of shows where that song was played
For each show, find the setlist
Find the shortest list of shows that contains every song
Of course, I underestimated the magnitude of the factorial function. That essentially rendered #4 impossible to solve, but I’m getting ahead of myself.
Getting the list of every song
I’m not accustomed to writing web scrapers, so I was hoping there’d be some API to the Phish.net database. They do have an API, but it seems to be for web developers through Javascript. After poking around there a little bit, I decided I’d have to go a more traditional route and go the scraper route. Fortunately with programming, a lot of the time you can simply use someone else’s code and start from there.
jsoup
I found jsoup, a Java HTML parser. This seemed to fit all of my needs. First, it has an online interface where you can test code without having to implement everything up front. Second, its free to use!
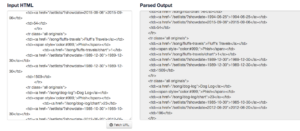
So you can simply tell jsoup to pull the source from any website. Since we’re looking for a list of every song Phish has played, the most obvious (and convenient) site to use was http://phish.net/songs. This gives the screenshot below, where the input and parsed output give clues as to what you’d be looking for.
Songs webpage parsed by jsoup
CSS Queries
If my aversion to web development hasn’t been obvious, it will start to become clear here. jsoup allows CSS Queries. I haven’t ever used CSS, but due to the user-friendliness of jsoup, I was able to quickly test queries. With a little intuition and some luck, I figured out that every song I wanted to look at was given the following line:
<tr class="all originals">
Assuing I’m only interested in originals, then I can use the CSS query of .originals in order to filter out everything that I don’t need.
Parsed by CSS class
Now I feel I’m getting close! I have been able to isolate the songs tagged as “originals” by the Phish.net folks. However, all of the additional links seem to muddy up the data – I don’t need to know “Alumni Blues Phish 106 1985-03-16 2016-07-20 29” I simply want “Alumni Blues”. A little more tinkering with CSS queries and I came across the “:first-of-type” argument. If I pull the first link (HTML type a) I get what I want.
Filtered to the first hyperlink
Halfway there!
Java Implementation
Now that I have everything working form the web interface, it’s time to look into the Java implementation. Essentially two magical lines of code will be able to pull an entire page and filter out the necessary “elements”.
Document document = Jsoup.connect("http://phish.net/songs").get();
Elements elements = document.select(".originals :first-of-type a");
With those two lines, there’s an object elements that can be used to loop over every song on the site! With three more lines of code (and two more classes that I won’t discuss) the entire list of songs can be created.
for (Element element : elements) {
Song song = new Song(element.text(), "http://www.phish.net/" + element.attr("href"));
songList.add(song);
}
After all that, we have a list of song names and, more importantly, URLs to information about the song.
Getting the rest of the data
I had alluded that the important part of the list of songs was actually the URL of the song. Using the same jsoup example from above, only instead of searching for the “.originals” class, the “.etpitem” is needed. With a little more code, you’ll end up with a list of all shows and using the “.setlist-song” class you’ll be able to pull all songs from every show.
After all of this, with a little bit of Java trickery, all the data can wrapped up in a couple of lists. This can be visualized by a simple mapping image.
Song to show mapping
Each song would be in the left box. Each arrow coming off each song indicates that song has been played in specific shows. The list of shows would be in the right box, and the arrows leading into them could be thought of the show’s setlist.
At this point everything related to scraping and organization is complete. The only thing left to do is simply solve the “minimum show list” that covers all of the songs.
The Algorithm
Recursion
In a lot of these projects I find myself leaning toward recursion whenever I can. Since I’ve been in the embedded world most of my career, I feel like recursion is often bad practice (if not explicitly forbidden.) This offered an interesting problem where a recursive brute-force method made sense…
Or so I thought…
The logic of the algorithm can be seen in the flowchart below. Not the best flowchart I’ve made, but deal with it. Hopefully the link stays active after my 1-week gliffy trial expires.
Recursive Algorithm Flow
There were a couple of intuitive tricks that I had used in this algorithm to help speed things up.
Early Exit
Near the top of the flowchart, I have what I called “Early Exit.” It is essentially a simple check to see if the number of songs left is possible to be covered by the number of shows left. For instance, if I have 100 songs left and only 2 shows left, I know that I won’t be able to cover all of those songs since Phish only played about 15-20 songs per show. In that case, I can exit the current processing stack. I called this an early exit, since I was able to kick out of the routine very “early” in the flowchart. Hopefully that’d speed up the selection algorithm quite quickly.
Sorted Selection
Another intuition I had was that I could start with songs that had been played only once or twice, and select those shows first. That is part of the “Least Played” part of the “Find Least Played, Unselected Song” step. Essentially if a song was only played once, it has to be in the minimum list of shows. So let’s select that show first. That way we don’t have to loop through the 597 times (at the time of writing this) that You Enjoy Myself has been played.
Code
The code to do all of this was probably easier to make than the Gliffy flowchart:
private static boolean chooseShow(final int numShowsToSelect) {
boolean rval = false;
// Check if we can exit early
if (numShowsToSelect * maxSongsPerShow < numSongsLeftToSelect) {
return false;
}
Song nextUnplayedSong = SongUtils.getNextUnplayedSong(songList);
if (nextUnplayedSong == null) {
// The "we're done" return
return true;
} else {
List currentShowList = nextUnplayedSong.getShowList();
for (Show currentShow : currentShowList) {
int numSongsAdded = currentShow.select();
numSongsLeftToSelect -= numSongsAdded;
if ( numSongsLeftToSelect == 0
|| chooseShow(numShowsToSelect - 1)) {
return true;
} else {
int numSongsRemoved = currentShow.unselect();
numSongsLeftToSelect += numSongsRemoved;
}
}
}
return false;
}
for (int numShowsToSelect = 1; numShowsToSelect < songList.size(); numShowsToSelect++) {
long startTime = System.nanoTime();
if (chooseShow(numShowsToSelect)) {
// Success!
System.out.println("Successfully got it with " + numShowsToSelect + " shows!");
break;
}
long endTime = System.nanoTime();
long duration = endTime - startTime;
System.out.println("Tried with " + numShowsToSelect + " shows - took: " + (duration / 1000000000.0) + " seconds");
}
Result
Nope.
By the time I hit 57 songs the algorithm was taking 20,000 seconds and increasing by a factor of 5 with every iteration. As it turns out, small numbers can become really, really big. There are about 10 million concert combinations with songs that were only played 5 times. And there are only 10 songs that were only played 5 times. In a true brute-force search, each of those had to be considered. Next.
Breadth First Search
For some reason, I had thought that the Breadth First Search (BFS) would have solved my issues from the recursive strategy. The reason being that each time I had to go “one deeper” the algorithm basically had to start over from scratch. This is a benefit of the BFS: It remembers the stack of operations that got you there, so that all you have to do is add each step to the processing queue. Wikipedia has a good enough explanation of BFS, so I’ll leave that as an exercise to the reader.
To explain this in further detail, I describe the final logic of the recursive algorithm as such:
Go to the next “Show”
Select each song from the show (add 1 to the play count)
If every song is selected, we’re done
If every song is not selected, unselect each song from the show
It can be see that we have to loop through each song, for each show. Not good! However, only one copy of the SongList is kept in memory, with their counts updated.
In the case of BFS, we’re using a processing queue. This means that every time we want to consider a new show, we have to copy the entire song and selected show arrays. So essentially the logic is:
Pop the next Show and UnplayedSongList off the Execution Queue
Remove each song played at the show from the UnplayedSongList
If the UnplayedSongList is empty, we’re done!
If the UnplayedSongList is not empty:
Find the next unplayed song
Add a copy of the UnplayedSongList and the next Show to the end of the Execution Queue
This led to a LOT of memory usage, since I had to make a copy of each selectedShowList, nextShow, and unplayedSongList for every show permutation. Further, the lookup from Show to Song was VERY quick in the recursive search method. Since these are copies of objects and not the objects themselves, there has to be an actual search for each song. NOTE: This could be done in O(logn), but even that is worse than O(1).
Long and the short of it
The recursive algorithm seemed to be much better than the BFS in this instance. It didn’t seem to take up much memory, though there were two loops over each setlist to mark / clear each song.
The BFS could be optimized so that I’m not copying the entire song list (URL, title, etc.) but I’m not confident that’ll work out either. There are simply too many possibilities.
Greedy algorithm
Here’s the sure fire way to come up with “A Solution.” It essentially involves the same process as the Depth First Search algorithm, but instead of trying every combination, it selects the “best” show it can find. The algorithm can simply be outlined as:
Find the song that has been been played the fewest times
From that song, find the show that selects the most unplayed songs
Select that show, and mark all those songs played
Doing this guarantees an answer (if the problem is solvable) but is not guaranteed to give the “best” answer.
Code
private static void doGreedyRoutine() {
Song nextUnplayedSong;
while ((nextUnplayedSong = SongUtils.getNextUnplayedSong(songList)) != null) {
List<Show> currentShowList = nextUnplayedSong.getShowList();
if (currentShowList == null) {
continue;
}
double showWeight = 0;
int optimalIndex = -1;
for (int i = 0; i < currentShowList.size(); i++) {
Show currentShow = currentShowList.get(i);
double tempShowWeight = currentShow.getShowWeight();
if (tempShowWeight > showWeight) {
showWeight = tempShowWeight;
optimalIndex = i;
}
}
if (optimalIndex > -1) {
Show selectedShow = currentShowList.get(optimalIndex);
selectedShow.select();
}
}
int i = 0;
for (Show showDisplay : showList) {
if (showDisplay.isSelected()) {
i++;
System.out.println(i + ". " + showDisplay.toString());
}
}
}
Results
We got something! The problem can be solved in at least 71 shows (as of the time I had scraped the Phish.net data)
This algorithm takes milliseconds to run, whereas the others took days and failed.
I’m saddened that I wasn’t able to get the “Absolute” solution down. I’m not yet convinced that it can’t be done, although I have done the math that suggests it probably can’t. That’ll be another post.
The next steps toward getting a better solution (I know for a fact that it can be done in fewer shows) are to REALLY optimize the search algorithm. This would mean running trials in parallel and trying to minimize the number of clock cycles per trial.
The final step would be to port the “optimized” code to an FPGA that has a lot of horsepower and see if a pipeline can be set up to really run through trials. Initial “Best Case Scenario” calculations suggest that it might take about 19 years of computing time, assuming one billion operations per second. So getting that down by a factor of hundreds is quite important. Could lead me to my first FPGA project…
If you’re anything like me, you’ve always been fascinated by Shazam. How is it possible to have a program that listens to a random portion of a random song through various microphones in various environments and come up with a song? For a while I chalked it up to black magic and intangible analysis, but I was led down the path of some fancy audio analysis that helped me make the jump to 10,000 foot understanding.
Fourier Transform
The first thing to get an understanding of is the Fourier Transform. Essentially this will take a signal (in the case of Shazam, a microphone signal) and determine the frequencies (pitches) that make up that signal. A bass guitar will have much lower frequencies than a piccolo. The Fourier Transform can yield important information about all of the pieces that make up what we actually hear. (Hint: Save for electronic sounds, all tones are made up of many different frequencies, leading to what is called timbre.)
The Fast Fourier Transform is what is typically used in the digital world. Your cell phone lives in the digital world. I’ll keep out how fascinating the FFT matrix actually is, and just leave the fact that in order to run an FFT on data, enough time has to be recorded. (If you want to find a 20 Hz signal, it helps to have more than 1/20 seconds.)
Windowed FFT
Now that there is some information about FFTs, I can get into more detail about Shazam. Sure, one can take a Fourier Transform of “In The Garden Of Eden” by I. Ron Butterfly, but that doesn’t really make sense unless you’re looking for underlying patterns. Where the powerful information comes out is when you look much closer. Since the human ear can only hear sounds as low as about 20 Hz, it makes sense to start around there – maybe take samples that can handle half that frequency. This would be 10 Hz, or 100ms of data.
Taking the frequency data of the first 100ms also doesn’t yield very interesting results either. You might be able to get an idea what the first few notes are. But what can happen is you could take another window from, say 1ms-101ms. You could keep doing this “windowed” FFT across the entire 17 minutes of In-a-gadda-da-vida, and you have all the data you need to analyze and catalog the song in a Shazam database!
This technique has been done in several facets of Arts and Engineering: Aphex Twin did it in 1999, Music Visualization Software has been doing it for decades, and there is a pitofWikipediapages one can dig through for weeks, if so inclined.
Mel-Frequency Cepstrum
I should mention this, though I feel it isn’t necessary for understanding. Back to how humans hear, the Mel-Frequency Cepstrum Coefficients are used to essentially make the frequencies from an FFT more relative to human hearing sensitivity. It helps to use, but isn’t necessary to understand the fundamentals.
Artifacts
At this point, I should cite the post that sparked my interest in this topic. https://blog.francoismaillet.com/epic-celebration/. He discusses (with images) the idea of using the MFCC to pull out specific sounds. Here he shows the relationship between a sound and the MFCC graph.
With a song, different things will show up in different ways. A singer’s voice, a cymbal crash, keyboard notes… Each of these sequences are unique to a song. Well, almost unique. But they essentially make up a fingerprint of the song.
I’ll leave out optimization (peak finding algorithms), but suffice it to say specific “points” can be found which have the “Maximum Intensity for a Frequency at a Time.” let’s just assume we can determine those with ease.
So now we have a bunch of points of frequency vs time. Using further ingenuity, these points can be cataloged in a database. That’ll possibly be worth another post in it’s own right. But essentially, all that is needed are a few points (differences in time and frequencies of artifacts) and that’s all that is needed for a Shazam match.
Conclusion
Since I didn’t have any sufficient graphs, this might have been a dry read. I’ll possibly fix this in the future. There is an article that I likely read several months / years ago that goes into more detail that can be found here. Shazam has been around for many years, and it wasn’t until I started down the path of some audio analysis that I was able to unveil some of the mysteries of a powerful tool that touches upon many points of Engineering / Computer Science.
First nerdy post here. If you’re anything like me, you’ve found yourself having to refactor your MySQL database more than once. In my case, every time I’ve re-IP’d my local network I have had to do this. This is because I’m using a MySQL database to maintain a synchronized list of media files across multiple instances of Kodi. Maybe that’ll be another post, but since I’ve had to do this more than once I figured I’d try to share this somewhere, if only for my own benefit.
Way back when I had used Python to tie into a MySQL database. I was “comfortable” with this at that time, so I chose Python as my language of choice.
Problem
The main problem that had to be solved was that the database points to a hard-coded local IP. This means that if I want to change my server’s IP from 192.168.1.10 to 192.168.2.10, I have to modify the database manually if I don’t want to lose anything.
Now, Kodi has an interesting database structure. The only thing to really take from that is that everything seems to point back to the main table “path”. Specifically the idPath / strPath pair. Notice that the strPath, below, has the hard-coded IP that I was mentioning. The goal is to change every entry in that table from “192.168.1.10” to “192.168.2.10”
Solution
Enter Python: There is a mysql.connector class that allows one to interact with MySQL from Python.
import mysql.connector
From here, you can connect to the database using your known database address, user name and password:
Now, the thing that I’m most concerned about is the strPath and the idPath. Since I know that idPath will be unique (… it is a database key) I can just select the two columns, refactor the string, and update each entry. First for the selection:
query='SELECT idPath, strPath FROM path'
cursor = cnx.cursor(buffered=True)
cursor.execute(query)
At this point, cursor has every entry of the ‘path’ table. The next thing to do is loop over every entry. Python’s loop syntax can be burdensome, but useful once figured out:
for (idPath, strPath) in cursor:
The next steps of refactoring and replacing are done in a single line of code – well two lines of code but still… Currently this is all in the for loop, but there’s no reason UpdateQuery2 couldn’t be placed in front of everything.
UpdateQuery2="UPDATE path SET strPath=%s WHERE idPath=%s"
cursor2.execute(UpdateQuery2, (strPath.replace('192.168.1.10','192.168.2.10'), idPath))
At this point, everything is buffered in the cursor2 object. I left the instantiation out earlier for simplicity, but will show it later. Once the loop is complete, the last thing to do is commit the transaction of cursor2:
cnx.commit()
After running this within Python I went back and looked at the path database and to my delight, everything was updated to the new IP address. I went back to Kodi and almost everything worked. (See improvement suggestions below)
Code
import mysql.connector
cnx = mysql.connector.connect(user='username', password='password', host='127.0.0.1', database='MyVideos107')
query='SELECT idPath, strPath FROM path'
cursor = cnx.cursor(buffered=True)
cursor2 = cnx.cursor()
cursor.execute(query)
for (idPath, strPath) in cursor:
UpdateQuery2="UPDATE path SET strPath=%s WHERE idPath=%s"
cursor2.execute(UpdateQuery2, (strPath.replace('192.168.1.10','192.168.2.10'), idPath))
cnx.commit()
Improvements
It’d be nice to be able to further automate this. For example, most versions of Kodi come out with an updated set of tables. It’d be nice to make this script smart enough to sweep through all of those.
Also, there are actually a number of tables where the static IP gets used – specifically the “art” table and “MyMusic” databases. The first step would be to make the above code allow input arguments of database name, key name, and string field name. Then a list of these values could be looped over to update everything.
Fortunately for me, this is somewhat of a rare occurrence. I re-IP’d when I decided to make a more logical allocation of DHCP reservations. I then had to re-IP in order to allow a graceful VPN into 192.168.1.X networks. So, hopefully I’ll never have to run this again. If I do, I’ll probably make those improvements.
Today was a work-on-the-place day. The goal was to attach a hood vent to our microwave. Initially it was simply venting out front into our kitchen (read spewing grease all over the shitty cabinets) and after some very low quality duct work, it is not attached to properly vent up through the attic.
Attempts were made to perform clean cuts with a jigsaw, however I couldn’t get close enough to the edge of the cabinets in order to make the cut I needed. This left me with two options: gracefully take the cabinet bottom off and lay it on a smooth surface in order to make clean, straight cuts, or perforate the stupid cabinets with a drill and knock it off with a hammer. I chose the latter.
So the jigsaw rental was a waste, but at least it was only a waste of a day’s rental: maybe $18 or so. Little did I know that you can buy a corded jigsaw for <$30, but that’s beside the point.
What followed was the destruction of some 7-inch semi-rigid ducting and some liberal use of duct tape as connectors and repair. The testing process was to turn on the fan and feel for a draft. Those faults were repaired with more duct tape.
After finishing that I had gotten the materials to try replacing the dimmer circuit in the bathroom which has never worked since we moved in. Now it works! Not really sure what the next project will be, or if this will continue. If it does, maybe I’ll decide to write a quip about it.









































{kind=link}